There is an acronym used by scientists called HARKing.
It describes a practice of Hypothesizing After The Results Are Known.
In the book “How to Make the World Add Up: Ten Rules for Thinking Differently About Numbers” by Tim Harford, the author describes these practices and calls out the dangers of doing so. The malpractice here is when a person comes up with a hypothesis different from their original to describe the already collected data and try to prove their point.
There’s no harm in creating a hypothesis for a new experiment based on available data but changing the hypothesis retrospectively is wrong.
In our own research into Experimentation Programs at Effective Experiments, we have encountered many CRO and testing teams and individuals engaging in this practice of HARKing. When we are asked to run audits and assessments of testing teams in enterprise organizations, we encounter examples of HARKing such as the ones below. Not all of them are about a hypothesis change but we will use this term to describe the other malpractices.
- Not crafting a strong hypothesis OR Changing the hypothesis at the end
- Not defining the metrics to track OR retrospectively changing or adding metrics which make the experiment look good
- Like above, cherry picking and only reporting on metrics that look good
- Launching experiments without any clear thought just to hit a target
- Rushing through or not following a process
They say choke your data long enough and it can tell you whatever story you want to hear.
The main cause for this is lack of oversight and without clear oversight and there’s no one to hold the practitioners accountable.
The secondary cause of this is how experimentation is currently viewed in organizations. There is pressure from management to hit KPIs that are targeted at the number of tests and revenue. (These are vanity metrics and you can read my thoughts about it here and here). As a result of this pressure, practitioners start cutting corners or changing the narrative of experiments.
Stakeholders love seeing positive results and experiments with big wins but what good is that if the results are not trustworthy?
Practitioners providing inaccurate data and insights are given full trust and it may be that the company only becomes aware of it too late or never. The cost of inaccurate data and insights is not just in money but it hampers the way experimentation can grow and hinder the innovation potential of that company.
The impact of this is organizations are flying blind and assuming they’re running a great experimentation program only to end up acting on faulty insights and results.
How do you solve the problem of HARKing?
The first way to solve this is probably a harder one.
If the senior leadership in an organization are unaware of this (and they likely are), a stronger governance framework and put guardrails needs to be put in place to prevent this from happening. In addition to this, there needs to be greater education for the C-level on the impact of this and the need for experimentation done right.
It’s easier said than done because getting oversight is not easy when different teams and individuals have a scattered approach in tracking their work. Different tools, different workflows, and varying levels of quality – all play a part in making it harder to create governance.
As experimentation programs have grown, individuals who have never run experiments before, such as product managers, are now tasked with running experiments. Their level of knowledge and experience means that they will never run high quality experiments, at least initially.
The second way which is easier but takes a lot of effort is by monitoring and coaching the teams that run experiments. If we can catch these issues early on and coach and provide feedback, this allows them to grow and get better at experimentation over time.
You need to create a system where every experiment is evaluated on its quality and not just the result. Experiment quality can be determined by how well the experiment is planned and executed and reported on and whether it stuck to that plan or not.
Experimentation teams struggle to visualise this quality because practitioners are moving from one experiment to the next and whilst they deal with the technical side of experimentation proficiently, they lack the bandwidth and the time to monitor and coach everyone.
HARK-ing happens when there is an unclear remit coupled with governance, accountability and a solid coaching culture.
To be able to visualise HARK-ing is a lot of effort if you are using multiple systems. We see teams struggle when their experimentation programs are tracked using a mix of Airtable, spreadsheets, powerpoints and other tools. This overhead and admin prevents teams from being introspective to learn where the blindspots are.
At Effective Experiments, we have seen the challenge this poses to enterprises trying to build an experimentation culture. We believe Experimentation programs need strong governance, guardrails and monitoring to help it grow in the company.
With that in mind, we have launched a new feature called Experiment Health Score.
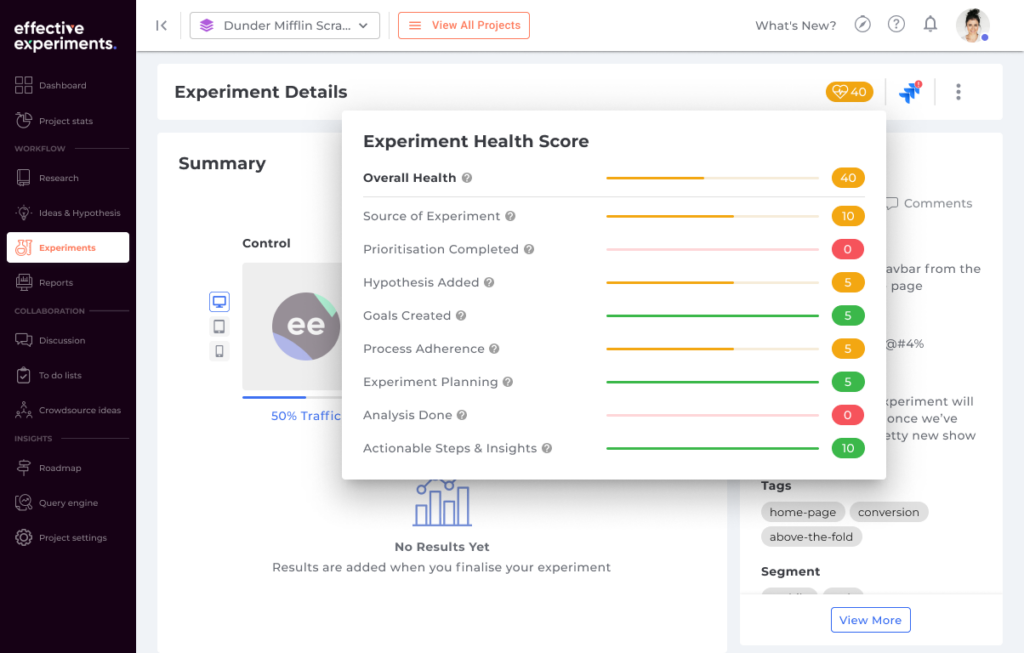
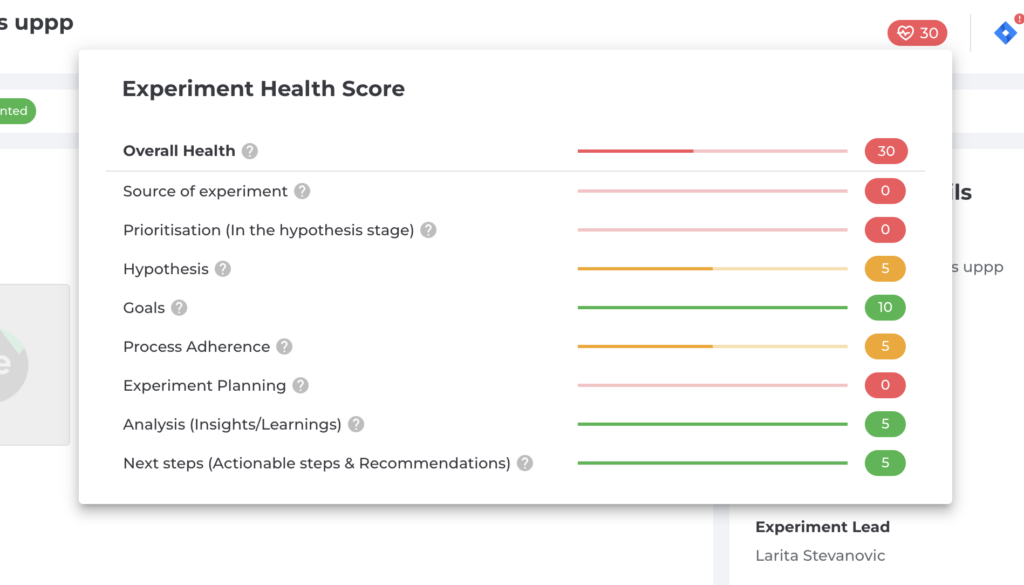
Customers using Effective Experiments to manage their organization’s experimentation efforts in our centralized program management solution will see automatic scoring on an experiment level, the team level and the program level.
The automated score will track how an individual or team plans, executes and reports on an experiment and if they deviate or do any HARK-ing practices. The scoring will happen during the planning stages as well as the reporting stages. Any changes to the integrity of the data and insights will be automatically detected.
Experimentation program managers will be able to effortlessly spot trends and coach the individuals or teams that may be HARK-ing resulting in a stable experimentation program that can scale up over time.
It is the first in our series of Experimentation Program Scorecard features that we have launched and is available to all our customers.
If you want a better way to manage your experimentation program without the hassle of managing multiple tools, then have a chat with myself or one of my team mates. See how our Experimentation Ops methodology, framework and platform can transform your enterprise’s experimentation program.